



Fermi技术细节抢先预览
为并行处理而生——第二代PTX指令集架构
PTX是NVIDIA针对支持并行线程处理运算而设计的低级虚拟机和ISA指令集。当程序执行之前,PTX指令会被GPU驱动转译为GPU的本机代码。此次,NVIDIA特别强调Fermi是第一个支持PTX 2.0的体系架构,而G80则是PTX 1.X。
高度整合——统一寻址空间
在PTX 1.x中,当load/store指令被执行的时候,需要指定三个寻址空间中的其中一个,程序才可以在编译时确定指定寻址空间中的load/store 数值。这样的计算能力很难提供完整的C和C++指针,因为在编译过程中很难确定一个指针的目标寻址空间。而PTX 2.0则实现了统一寻址空间,把三个寻址空间都统一为一个单独、连续的寻址空间。
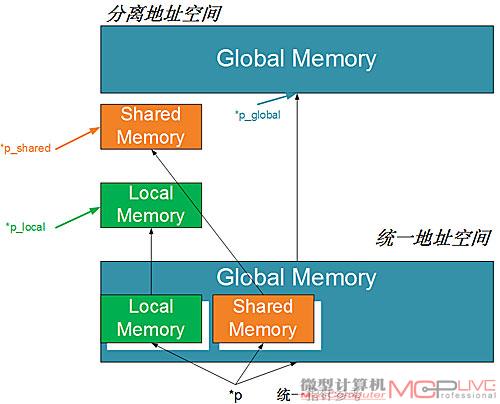
有了统一寻址空间以后,就只需要一组Load/Store指令
因此只需一组Load/Store指令,而不再需要三套针对不同寻址空间的Load/Store指令。此外,PTX 2.0还增加了C++虚拟函数、函数指针,针对动态分配对象、解除分配的“new”和“delete”操作以及针对异常处理操作的“try”和“catch”。
针对OpenCL和DirectCompute的优化
OpenCL、DirectCompute与CUDA的编程模型有非常密切的对应关系,CUDA里的Thread、Thread block、Grid、障栅同步、shared memory、global memory以及原子操作都能在OpenCL和DirectCompute中看到,因此基于Fermi的GPU在运行OpenCL和DirectCompute时会更加得心应手。此外,Fermi架构还为OpenCL和DirectCompute的表面(surface)格式转换指令提供了硬件支持,允许图形与计算程序能简单地对相同的数据进行操作。同时,PTX 2.0还为DirectCompute提供了population count、append以及bit-reverse指令的支持。
浮点运算好帮手——支持IEEE 754-2008规范
在浮点运算方面,G80、GT200的单精度运算都是采用IEEE 754-1985标准的浮点算法,Fermi在单精度浮点指令上提供了对次常数(subnormal number,即denormal number或者denormalized number)以及IEEE754-2008标准的所有四种舍入模式(nearest、zero、positive infinity、negative infinity)的支持。
什么是次常数
次常数指的是在定浮点数系统中分布于小正数和大负数之间的数。小正数和大负数取决于系统的设定。假设大负数是-1,小正数是1,在-1和1之间的数就是次常数。
面对次常数,CPU通常将其视作异常情况,会以软件方式进行计算,这需要消耗数千个周期。而过去GPU针对次常数的应对措施并不多,一般GPU会将这个范围内的数据冲刷成零,但会导致精度的损失。而Fermi的浮点单元能以硬件方式处理次常数,允许它们逐渐下溢至零而不至于导致精度的损失。在电脑图形、线性代数和科学应用中常见的运算操作是把两个数相乘,然后将获得的结果与第三个数相加,例如C=A×B+C。以往的GPU会使用multiply-add(MAD)指令来实现上述运算。不过MAD指令中在进行乘法计算(例如 C=A×B+C中的A×B)的时候容易出现一些非常小的尾数。尾数会被切掉,并在接下来的加法运算中使用“舍入到近偶数”的方式作舍入操作。
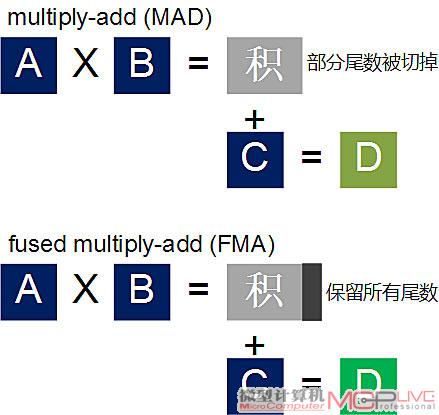
FMA指令可以避免精度的损失
无论是32-bit运算还是64-bit运算,Fermi均使用fused multiply-add(FMA)指令来执行(GT200只对64-bit运算采用FMA指令),可以保证乘法运算的结果以全精度的形式保留。和MAD(multiply-add)指令相比,FMA指令在做乘法和加法运算时只在末做一次四舍五入,不会在执行加法的时候就出现精度损失。提升精度可以让多种算法获益,例如精密的交叉几何体渲染、迭代数学方面的高精度计算以及快速准确舍入的除法与平方根操作。
智能追踪——predication论断
PTX 2.0为所有的指令提供了predication(论断)支持,这会提升执行效率。在采用分支指令执行"if-else(如果-否则)"条件语言的时候,SM必须了解哪些线程在条件中的什么路径中执行;当有额外的分子路径发生时(taken),硬件都会跟踪一组,这会增加线程组。但当条件语言使用论断的话,就能比分支指令更有效,因为只有那些符合的条件测试线程才会被写入到目标寄存器中,其它的线程不会发生改变。
用户评论
-
-
-
事实上NV现在是不是技术的成功者也值得探讨。N和A的架构孰优孰劣只能透过实际检验来衡量,事实上如果所有的测试或者游戏都关闭了优化的元素之后,两家厂商的芯片性能其实一直是在伯仲之间。 Fermi的架构看图的确很吸引人,但是NV忘了一样东西,那就是想象可以无限大,但是后却都只能立足于一片小硅片之上。随着GPU功能的复杂化,制程的更新已经明显跟不上,Fermi迟迟不能生产就是好的例子。NV继续坚持大芯片的道路现在看来无疑是错误的。 事实上NV的确很厉害,它拥有一大堆自有标准,例如PhysX和CUDA。它的确一呼百应,一大堆THE WAY游戏就是证明。但是,今天的NV和当初的3dfx何其相似,抱着自有的标准,做着黄粱美梦。事实上,任何的标准都可以有替代品。当年DirectX替代了GLIDE,今天同样Direct Computing和OpenCL可以替代CUDA和PhysX。希望NV还是要踏踏实实做好芯片的研发,不要以为自有标准是万能的。所谓的合作伙伴都是商人,商人是唯利是图的,当年他们可以抛弃3dfx,今天就可以抛弃NV。
-
-

