



Fermi技术细节抢先预览
和Fermi架构息息相关——CUDA编程模型的原理
理解CUDA编程模型的原理有助于我们进一步认识Fe rmi架构。CUDA由硬件和软件架构共同组成,即必须在支持CUDA的NVIDIA GPU上,利用CUDA C语言编译器以及围绕NVIDIA GPU开发的各种工具才能进行CUDA计算。这个架构可以让NVIDIA GPU执行由C、C++、Fortran、OpenCL、DirectCompute以及其它语言所编写的程序。
在GPU内执行的CUDA程序被称作并行kernel,kernel是通过一系列平行、互不依赖的Thread(线程)以并行的方式来执行。GPU会将一个kernl程序模拟成一个由若干个Thread block(线程块,由Thread组成,Thread block=512Thread)组成的Grid(线程块格)。

在CUDA的编程模型中,Warp、Thread、Thread block和Grid是很重要的
在CUDA中,每个Thread 都有一块per-Thread private memory的私有空间又被称作 local memory),用于寄存器溢出、函数调用(function call)。每个Thread Block都有自己的一块per-block shared memory空间,用于Thread Block内线程间的通信、数据共享以及并行算法中的中间结果共享。
Thread、Thread block和Grid之间的关系
在执行kernel程序时,很有可能需要进行Thread之间的共享、临时数据交换。为了实现高效的Thead 共享、临时数据交换,就必须将一堆Thread组织起来,这个组织起来的单位就是Thread block。
Thread Block指的是能通过障栅同步和Shared memory彼此协作的一组并发执行线程。在G80和GT200中,每个Thread Block多拥有512个并发线程。而在Fermi中,每个Thread Block多可以有1536个并发线程。在Grid中,每个Thread Block都有自己的ID。
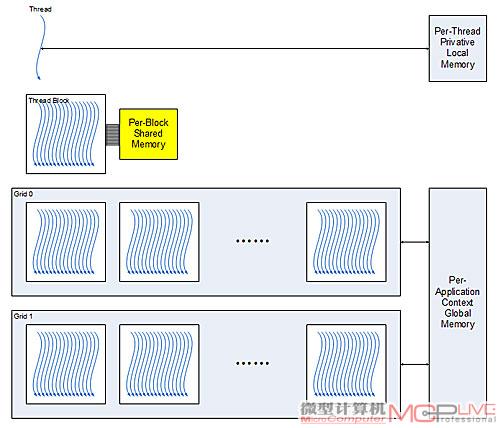
Thread是组成Thread block和Grid的原始单位
在Thread block内,每个Thread执行kernel内的一个instance(实例,例如一个像素或者像素中的一个色元等),每个Thread 都有自己的Thread ID、program counter(程序计数器)、register(寄存器)、per-Thread private memory(逐线程专有存储器)、input(输入)以及output result(输出结果)。
Grid就是一个由多个Thread block组合而成的矩阵,需要从Global Memory中读取Input以及往Global Memory中写入结果。
用户评论
-
-
-
事实上NV现在是不是技术的成功者也值得探讨。N和A的架构孰优孰劣只能透过实际检验来衡量,事实上如果所有的测试或者游戏都关闭了优化的元素之后,两家厂商的芯片性能其实一直是在伯仲之间。 Fermi的架构看图的确很吸引人,但是NV忘了一样东西,那就是想象可以无限大,但是后却都只能立足于一片小硅片之上。随着GPU功能的复杂化,制程的更新已经明显跟不上,Fermi迟迟不能生产就是好的例子。NV继续坚持大芯片的道路现在看来无疑是错误的。 事实上NV的确很厉害,它拥有一大堆自有标准,例如PhysX和CUDA。它的确一呼百应,一大堆THE WAY游戏就是证明。但是,今天的NV和当初的3dfx何其相似,抱着自有的标准,做着黄粱美梦。事实上,任何的标准都可以有替代品。当年DirectX替代了GLIDE,今天同样Direct Computing和OpenCL可以替代CUDA和PhysX。希望NV还是要踏踏实实做好芯片的研发,不要以为自有标准是万能的。所谓的合作伙伴都是商人,商人是唯利是图的,当年他们可以抛弃3dfx,今天就可以抛弃NV。
-
-

